How AITR Masters LLM Fine-Tuning: A Deep Dive into Open-Source Models and Langchain
At AITR, we’re constantly pushing the boundaries of what’s possible with Large Language Models (LLMs). In this post, we’ll explore the intricate world of fine-tuning open-source LLMs, with a particular focus on using Langchain. We’ll delve into the technical aspects of neural network training and provide practical insights for startups looking to leverage these powerful tools for managers and developers.
Understanding LLMs and Fine-Tuning
Large Language Models are neural networks trained on vast amounts of text data, capable of understanding and generating human-like text. While pre-trained models like GPT-4 or BERT offer impressive out-of-the-box performance, fine-tuning allows us to adapt these models to specific domains or tasks, significantly enhancing their effectiveness for specialized applications.
Fine-tuning involves further training a pre-trained model on a smaller, task-specific dataset. This process adjusts the model’s weights to better fit the target domain while retaining the general knowledge acquired during pre-training.
The Power of Open-Source LLMs
Open-source LLMs, such as BERT, LLAMA, or GEMMA, offer several advantages:
Customizability: Developers can modify the model to suit specific needs.
Cost-effectiveness: No need for expensive API calls to closed-source models.
Privacy: Data can be processed locally, ensuring confidentiality.
Fine-Tuning with Langchain
Langchain is a powerful framework that simplifies working with LLMs. It provides a set of tools and abstractions that make it easier to build applications with LLMs, including fine-tuning capabilities.
Here’s a basic example of how you might use Langchain for fine-tuning:
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# Initialize the LLM
llm = OpenAI(model_name="text-davinci-002")
# Define a prompt template
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
# Create an LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain
print(chain.run("eco-friendly water bottles"))Or:
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.callbacks import ModelCallbackHandler
# Custom callback handler for fine-tuning
class FineTuningHandler(ModelCallbackHandler):
def on_llm_new_token(self, token: str, **kwargs) -> None:
print(f"New token: {token}")
# Initialize the LLM with fine-tuning parameters
llm = OpenAI(
model_name="text-davinci-002",
temperature=0.7,
max_tokens=100,
n=1,
best_of=1,
frequency_penalty=0,
presence_penalty=0,
stop=None,
callbacks=[FineTuningHandler()]
)
# Define a prompt template for fine-tuning
prompt = PromptTemplate(
input_variables=["context", "question"],
template="Context: {context}\nQuestion: {question}\nAnswer:",
)
# Create an LLMChain for fine-tuning
chain = LLMChain(llm=llm, prompt=prompt)
# Fine-tuning data
fine_tuning_data = [
{"context": "AI Tech Report specializes in code analysis.", "question": "What does AI Tech Report do?"},
{"context": "LLMs are neural networks trained on vast amounts of text.", "question": "What are LLMs?"},
# Add more fine-tuning examples here
]
# Fine-tune the model
for data in fine_tuning_data:
chain.run(data)
# Test the fine-tuned model
result = chain.run({"context": "AI Tech Report uses LLMs for code analysis.", "question": "How does AI Tech Report use AI?"})
print(result)This example demonstrates how to set up a fine-tuning process using Langchain. It creates a custom callback handler to monitor the fine-tuning progress, initializes an LLM with specific parameters, and then runs the model through a series of fine-tuning examples.
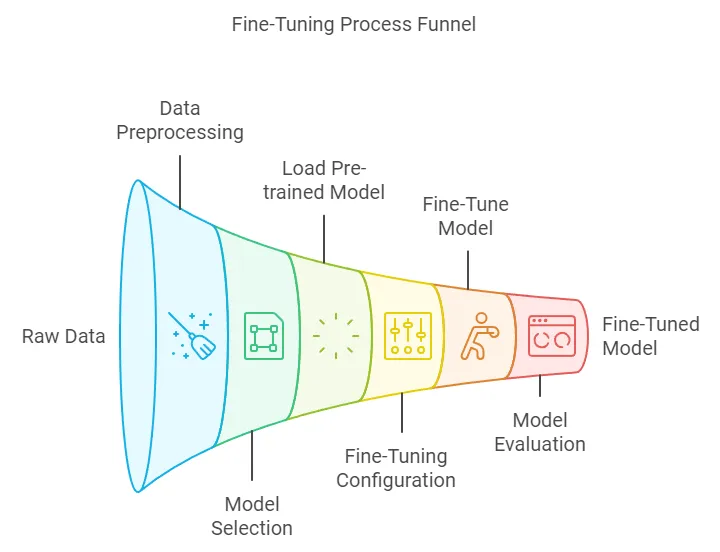
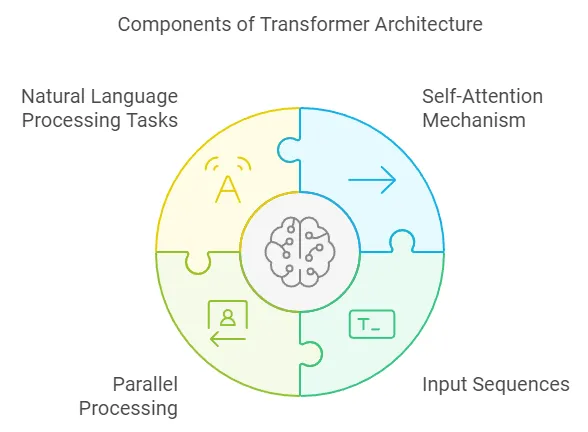
Neural Network Training: The Backbone of LLMs
To truly understand LLMs and fine-tuning, it’s crucial to grasp the fundamentals of neural network training. At its core, an LLM is a deep neural network, typically based on the Transformer architecture.
The Transformer Architecture
Transformers, introduced in the landmark paper “Attention Is All You Need” (Vaswani et al., 2017), use self-attention mechanisms to process input sequences in parallel, allowing for more efficient training on large datasets.
Key components of a Transformer include:
Embedding layers
Multi-head attention mechanisms
Feed-forward neural networks
Layer normalization
Training Process
The training process for LLMs involves several key steps:
Data Preparation: Collecting and preprocessing a large corpus of text data.
Tokenization: Converting text into numerical tokens that the model can process.
Forward Pass: Passing tokenized input through the network to generate predictions.
Loss Calculation: Comparing predictions to actual outputs to compute the loss.
Backpropagation: Calculating gradients of the loss with respect to model parameters.
Parameter Update: Adjusting model weights to minimize the loss, typically using optimizers like Adam or SGD.
This process is repeated over many iterations, with the model gradually improving its ability to predict the next token in a sequence.
Fine-Tuning Specifics
When fine-tuning, we start with a pre-trained model and continue training on a smaller, domain-specific dataset. This process involves:
Freezing Layers: Often, early layers of the model are frozen (weights kept constant) to preserve general language understanding.
Adjusting Learning Rates: Typically, lower learning rates are used to avoid catastrophic forgetting.
Task-Specific Modifications: For some tasks, additional layers or output heads may be added to the model.
Careful Monitoring: Overfitting is a significant risk in fine-tuning, so validation performance must be closely tracked.
Practical Considerations for Startups
When implementing LLM fine-tuning in your startup:
Data Quality: Ensure your fine-tuning dataset is high-quality and representative of your target domain.
Computational Resources: Fine-tuning can be computationally intensive. Consider cloud GPU resources if needed.
Evaluation Metrics: Define clear metrics to evaluate the performance of your fine-tuned model.
Ethical Considerations: Be aware of potential biases in your training data and model outputs.
Iterative Approach: Start with a small fine-tuning experiment and gradually scale up based on results.
Conclusion: Transforming Software Development with AI-Powered Insights
Fine-tuning open-source LLMs using frameworks like Langchain offers startups a powerful way to create specialized AI models without the need for training from scratch. By understanding the underlying principles of neural network training , you can adapt state-of-the-art language models to your specific needs, driving innovation and creating unique value for your users.
Empowering Developers and Managers
By harnessing the power of fine-tuned open-source LLMs, AI Tech Report provides unprecedented insights that benefit both developers and managers:
Enhanced Code Review: Our AI models, trained on vast codebases and fine-tuned for specific languages and frameworks, can identify potential bugs, security vulnerabilities, and code smells with remarkable accuracy. This not only speeds up the code review process but also catches issues that might be missed by human reviewers.
Developer Productivity Boost: With AI-powered suggestions and automated refactoring recommendations, developers can focus on solving complex problems rather than getting bogged down in routine tasks. This leads to increased job satisfaction and more efficient use of developer time.
Data-Driven Management Insights: Managers gain access to detailed analytics on team performance, code quality trends, and project health. These insights enable data-driven decision-making, helping to allocate resources effectively and identify areas for process improvement.
Predictive Project Management: By analyzing historical data and current trends, our AI models can predict potential bottlenecks, estimate completion times more accurately, and suggest proactive measures to keep projects on track.
Driving Business Value
The implementation of AI-powered code analysis and team insights translates directly into tangible business benefits:
Cost Reduction: By automating routine tasks and identifying issues early in the development process, AI Tech Report helps reduce the time and resources spent on debugging and refactoring. This can lead to significant cost savings, especially for larger projects or teams.
Quality Improvement: Consistent, AI-driven code reviews ensure higher code quality across the board. This results in more stable, maintainable software and reduced technical debt, saving costs in the long run.
Faster Time-to-Market: With streamlined development processes and early issue detection, teams can deliver features and products faster without compromising on quality.
Risk Mitigation: Advanced security vulnerability detection helps prevent costly data breaches and reputational damage.
Team Optimization: Insights into individual and team performance allow for targeted training, better task allocation, and improved team dynamics.
The Future of Software Development
As we continue to push the boundaries of what’s possible with AI in software development, we envision a future where AI becomes an indispensable partner in the development process. Imagine a world where:
AI pair programmers work alongside human developers, offering real-time suggestions and catching errors as they’re typed.
Automated code generation handles routine tasks, allowing developers to focus on innovation and complex problem-solving.
AI-driven project management systems adapt in real-time to changing conditions, ensuring optimal resource allocation and project outcomes.
At AITR, we invite you to join us on this exciting journey. Whether you’re a startup founder looking to optimize your development processes, a project manager seeking data-driven insights, or a developer eager to leverage cutting-edge AI tools, AI Tech Report is here to empower you.
Remember, the key to success with LLMs and AI in software development is not just in the technology itself, but in how creatively and effectively you apply it to solve real-world problems. With AI Tech Report, you’re not just adopting a tool — you’re embracing a new paradigm of intelligent, efficient, and innovative software development.
Let’s code smarter, lead stronger, and build the future of software development together.
Bruno Laureano Co-Founder and CTO.